PMPP 第二章 异构数据并行计算
本章主线
本章用一个简单的向量加法例子说明 CUDA C++ 的基本编程结构:
CPU / host 负责控制流程、分配显存、传输数据、调用 kernel;
GPU / device 负责启动大量线程,并行执行 kernel 中的计算。
核心问题可以概括为:
如何把原来 CPU 上的串行循环,
改写成 GPU 上大量 thread 同时处理不同数据元素。
2.1 数据并行
数据并行(data parallelism) 指的是:对数据集不同部分执行的计算彼此独立,因此可以并行完成。
例如图像灰度化中,每个像素的亮度只依赖该像素自己的 RGB 值:
不同像素之间没有依赖关系,因此每个像素都可以由一个独立线程处理。
数据并行适合 GPU 的原因是:
数据量大;
每个数据元素上的计算相似;
不同元素之间依赖少;
可以启动大量线程同时处理。
与之相对的是 任务并行(task parallelism):不同任务之间可以独立执行,例如一个程序中同时存在向量加法、矩阵向量乘法、I/O、数据传输等任务。
一般来说,大规模并行程序的主要性能来源通常是数据并行;任务并行也重要,但更多用于组织不同阶段或隐藏开销。
2.2 CUDA C++ 编程结构
CUDA C++ 可以理解为:
CUDA C++ = C++ + CUDA 扩展语法 + CUDA Runtime API
CUDA 程序面向 host + device 的异构系统:
| 角色 | 对应硬件 | 职责 |
|---|---|---|
| host | CPU | 执行普通 C++ 代码,控制程序流程,调用 kernel |
| device | GPU | 执行 kernel,进行大规模并行计算 |
普通 C++ 代码默认运行在 host 上。只有带 CUDA 修饰符的函数,才是 device 相关代码,例如:
__global__ void kernel(...) {
// device code
}
CUDA 程序的典型执行流程是:
CPU 执行 host code
↓
CPU 调用 kernel
↓
GPU 启动大量 threads 并行执行 kernel
↓
kernel 完成
↓
控制权回到 CPU
kernel 是运行在 GPU 上的函数。一次 kernel 调用会启动一个 grid,grid 中包含大量 GPU threads,这些线程并行执行同一段 kernel 代码。
核心理解:
host code 是控制逻辑;
device code 是并行计算逻辑;
kernel launch 是 CPU 启动 GPU 并行计算的入口。
2.3 向量加法例子
向量加法是最简单的数据并行例子:
C[i] = A[i] + B[i];
每个 C[i] 只依赖 A[i] 和 B[i],不同元素之间没有依赖。
普通 C++ 版本通常写成:
void vecAdd(float* A_h, float* B_h, float* C_h, int n) {
for (int i = 0; i < n; i++) {
C_h[i] = A_h[i] + B_h[i];
}
}
这里 _h 表示 host 侧数据,即 CPU 内存中的数组。
CUDA 版本不能只把 for 循环搬到 GPU 上,而是要完成三件事:
1. 把输入数据从 CPU 内存复制到 GPU 显存;
2. 调用 kernel,在 GPU 上并行计算;
3. 把结果从 GPU 显存复制回 CPU 内存。
因此,CUDA 版 vecAdd 更像一个 host stub / 调度壳子:它本身不做逐元素计算,而是负责数据准备、kernel 调用和结果回收。
需要注意的是,频繁 host-device 数据传输可能成为性能瓶颈。实际高性能 CUDA 程序通常会尽量让数据长期保留在 GPU 上,并连续执行多个 kernel,减少来回拷贝。
2.4 Device Global Memory 与数据传输
GPU 有自己的显存,称为:
device global memory
CPU 使用的是 host memory,GPU kernel 访问的是 device global memory。因此,host 侧数组不能直接交给 kernel 使用,必须先分配 GPU 显存并复制数据。
典型数据流是:
输入:
A_h, B_h 位于 CPU 内存
↓ cudaMemcpyHostToDevice
A_d, B_d 位于 GPU 显存
输出:
C_d 位于 GPU 显存
↓ cudaMemcpyDeviceToHost
C_h 位于 CPU 内存
cudaMalloc
cudaMalloc 用于在 GPU 显存中分配空间:
float* A_d;
int size = n * sizeof(float);
cudaMalloc((void**)&A_d, size);
注意:
size 的单位是 byte;
cudaMalloc 需要修改 A_d 的值,所以传入 &A_d;
(void**) 是为了匹配通用指针接口。
cudaFree
cudaFree 用于释放 GPU 显存:
cudaFree(A_d);
这里传 A_d,不是 &A_d,因为释放时只需要知道要释放哪段显存,不需要修改指针变量本身。
cudaMemcpy
cudaMemcpy 用于 host 和 device 之间复制数据:
cudaMemcpy(dst, src, size, kind);
常见方向包括:
cudaMemcpy(A_d, A_h, size, cudaMemcpyHostToDevice);
cudaMemcpy(C_h, C_d, size, cudaMemcpyDeviceToHost);
参数顺序始终是:
目标地址,源地址,字节数,拷贝方向
device pointer 的限制
A_d、B_d、C_d 是 device pointer,保存的是 GPU 显存地址。它们可以在 host code 中作为变量保存和传递,但不能在 host code 中直接解引用。
错误理解:
printf("%f\n", A_d[0]); // 不应在 CPU 侧直接访问 GPU 显存
正确用途:
传给 cudaMemcpy;
传给 cudaFree;
传给 kernel。
2.5 Kernel Functions and Threading
kernel 是由大量 GPU threads 并行执行的函数。CUDA kernel 采用典型的 SPMD(Single-Program Multiple-Data) 模型:
所有线程执行同一份代码;
不同线程根据自己的编号处理不同数据。
CUDA 线程采用两级组织结构:
grid
├── block 0
│ ├── thread 0
│ ├── thread 1
│ └── ...
├── block 1
│ ├── thread 0
│ └── ...
└── ...
一次 kernel launch 启动一个 grid;一个 grid 包含多个 block;一个 block 包含多个 thread。
常见 block size 有 128、256、512 等,通常取 32 的倍数。一个 block 的线程数有硬件上限,常见最大值是 1024。
线程编号
kernel 中常用三个内置变量:
| 变量 | 含义 |
|---|---|
threadIdx |
当前 thread 在 block 内的编号 |
blockIdx |
当前 block 在 grid 内的编号 |
blockDim |
每个 block 的维度,即每个 block 有多少 thread |
对于一维向量加法,通常使用 .x 字段:
int i = blockIdx.x * blockDim.x + threadIdx.x;
这句代码把线程编号映射成数组下标:
blockIdx.x * blockDim.x:当前 block 前面已有多少线程;
threadIdx.x:当前线程在本 block 内的位置;
二者相加:当前线程在整个 grid 中的全局编号。
向量加法 kernel 可以写成:
__global__
void vecAddKernel(float* A, float* B, float* C, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
C[i] = A[i] + B[i];
}
}
其中 if (i < n) 用于防止多启动的线程访问越界。因为 n 不一定能被 block size 整除,实际启动的线程数通常会略大于数据元素个数。
函数修饰符
CUDA C++ 中常见的函数修饰符:
| 修饰符 | 调用位置 | 执行位置 | 含义 |
|---|---|---|---|
__global__ |
host 调用 | device 执行 | kernel 函数,调用后启动 grid |
__device__ |
device 调用 | device 执行 | GPU 端普通函数 |
__host__ |
host 调用 | host 执行 | CPU 端普通函数 |
普通 C++ 函数默认就是 __host__。如果写成:
__host__ __device__
float f(float x) {
return x * x;
}
则编译器会生成 CPU 和 GPU 两个版本。
2.6 Calling Kernel Functions
kernel 调用不是普通函数调用,而是带有执行配置参数:
kernel<<<gridDim, blockDim>>>(args);
在向量加法中常写成:
int threadsPerBlock = 256;
int numBlocks = (n + threadsPerBlock - 1) / threadsPerBlock;
vecAddKernel<<<numBlocks, threadsPerBlock>>>(A_d, B_d, C_d, n);
其中:
threadsPerBlock:每个 block 中有多少 thread;
numBlocks:grid 中有多少 block。
numBlocks 要向上取整,保证线程总数不少于数据元素个数:
numBlocks × threadsPerBlock >= n
多出来的线程由 kernel 内部的边界判断过滤:
if (i < n) {
C[i] = A[i] + B[i];
}
完整的 CUDA 版向量加法结构可以概括为:
void vecAdd(float* A_h, float* B_h, float* C_h, int n) {
float *A_d, *B_d, *C_d;
int size = n * sizeof(float);
cudaMalloc((void**)&A_d, size);
cudaMalloc((void**)&B_d, size);
cudaMalloc((void**)&C_d, size);
cudaMemcpy(A_d, A_h, size, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B_h, size, cudaMemcpyHostToDevice);
int threadsPerBlock = 256;
int numBlocks = (n + threadsPerBlock - 1) / threadsPerBlock;
vecAddKernel<<<numBlocks, threadsPerBlock>>>(A_d, B_d, C_d, n);
cudaMemcpy(C_h, C_d, size, cudaMemcpyDeviceToHost);
cudaFree(A_d);
cudaFree(B_d);
cudaFree(C_d);
}
需要注意:不同 block 的执行顺序不由程序员控制。因此,kernel 不能依赖 block 按编号顺序执行。向量加法可以并行,是因为每个元素计算独立,不需要 block 之间同步。
2.7 Compilation
CUDA C++ 使用了普通 C++ 编译器不认识的扩展语法,例如:
__global__
__device__
__host__
kernel<<<gridDim, blockDim>>>(args)
threadIdx / blockIdx / blockDim
因此 CUDA 程序需要使用 NVCC(NVIDIA CUDA Compiler) 编译。
NVCC 会把代码分成两部分处理:
host code → 交给普通 C/C++ 编译器处理;
device code → 编译成 PTX,再由设备端 JIT 编译器生成适合当前 GPU 的代码。
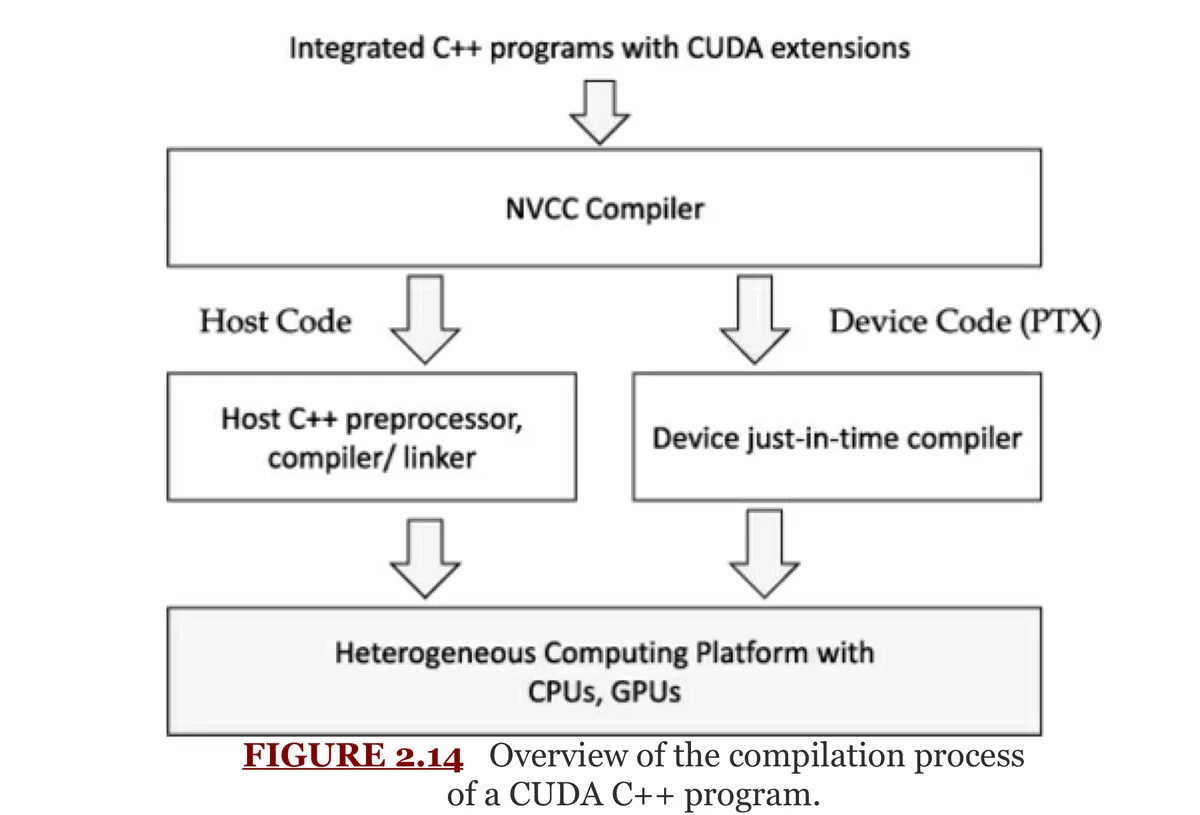
简化流程是:
CUDA C++ source
↓
NVCC
/ \
host code device code
↓ ↓
C++ 编译器 PTX
CPU 代码 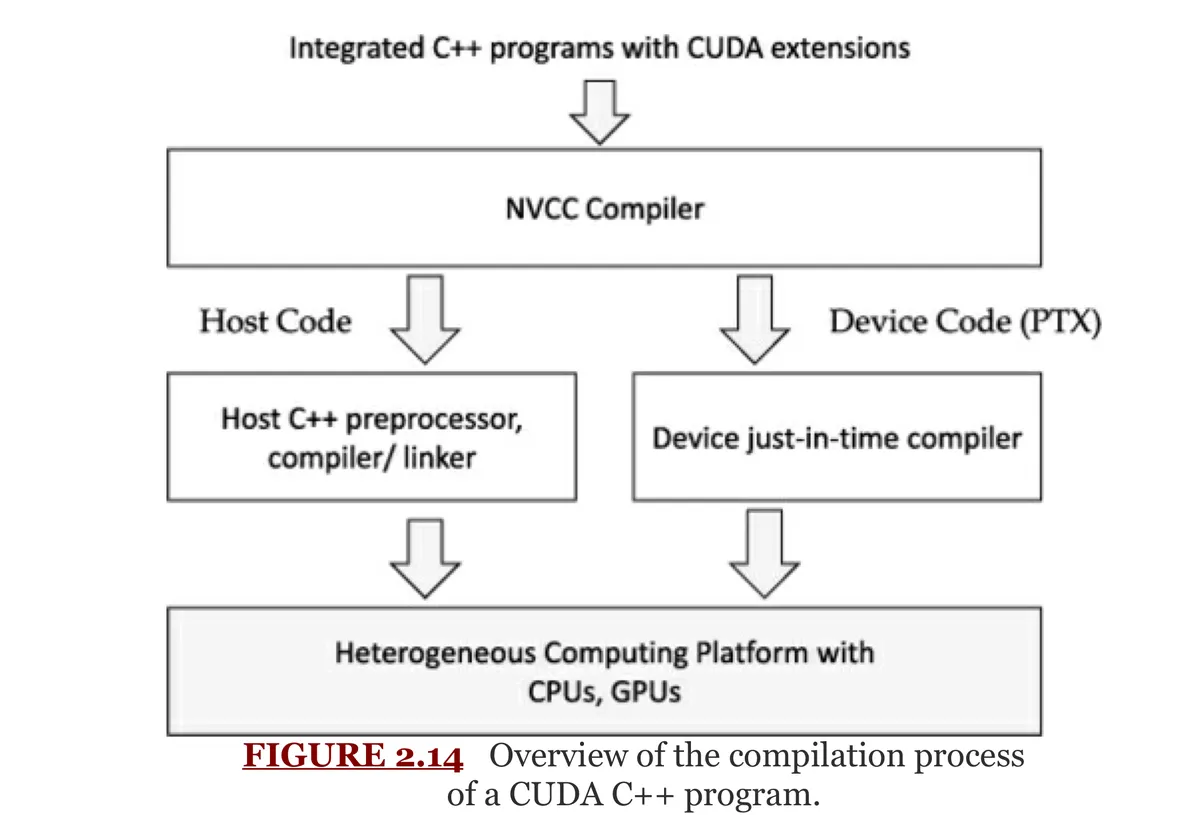
device JIT
\ /
CPU + GPU 异构程序
核心理解:
CUDA 源码中 host code 和 device code 写在一起;
但编译时由 NVCC 分开处理;
最后组合成能在 CPU + GPU 平台上运行的程序。
2.8 本章总结
本章介绍了写一个简单 CUDA C++ 程序所需的最小核心集合:
| 分类 | 内容 | 需要掌握 |
|---|---|---|
| 函数修饰符 | __global__、__device__、__host__ |
区分 kernel、device 函数、host 函数 |
| kernel 调用 | kernel<<<gridDim, blockDim>>>(args) |
host 如何启动 GPU grid |
| 内置变量 | threadIdx、blockIdx、blockDim |
thread 如何计算自己的数据下标 |
| Runtime API | cudaMalloc、cudaMemcpy、cudaFree |
host 如何管理显存和数据传输 |
| 编译工具 | NVCC | host/device 分离编译 |
最重要的代码模式有两个。
第一,线程映射数据:
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
C[i] = A[i] + B[i];
}
第二,host 侧调用 kernel:
int threadsPerBlock = 256;
int numBlocks = (n + threadsPerBlock - 1) / threadsPerBlock;
vecAddKernel<<<numBlocks, threadsPerBlock>>>(A_d, B_d, C_d, n);
一句话概括本章:
CUDA C++ 程序由 host code 负责控制流程和数据搬运,由 device kernel 负责并行计算;程序员通过 grid/block/thread 组织大量线程,并用线程编号把计算映射到不同数据元素上。
2.9答案
i = blockIdx.x * blockDim.x + threadIdx.x
i = 2 * (blockIdx.x * blockDim.x + threadIdx.x)
i = 2 * blockIdx.x * blockDim.x + threadIdx.x
8192
v * sizeof(int)
(void **)&A_d
cudaMemcpy(D_d, H_h, 3000, cudaMemcpyHostToDevice);
cudaError_t err;
a.
128
b.
200064
c.
1563
d.
200064
e.
200000
- 使用__host__, __device__修饰